YCAM InterLab Camp vol. 3 was a three-day intensive workshop to help participants learn the basic concepts and potential applications of biotechnology. It was held from March 1st through the 3rd, 2019. This article is a report on the third day of the event. Click here to read the article for the first day, or see the home page for an overview of the event.
Starting day 2 with an exercises that “causes glitches in the sensory perceptions”
The 2nd day of the workshop started at 9:30 a.m. The main work for the morning session was analyzing the DNA data that was sequenced overnight.
This day’s program also started with an exercise led by contact Gonzo. They instructed the participants to randomly walk around and intentionally bump into each other. Every time we bumped into someone, we were not allowed to utter any sounds and had to remain as expressionless as possible. In other words, we tried to communicate with each other just by the collided body parts and the strength of that impact.
As they walked around the room, the participants made contact with each other using different parts of their bodies, such as arms, shoulders, and backs.
The repeated contacts started to generate an odd feeling of trust and the collisions gradually became more forceful. Even strong impacts that would definitely cause trouble on a crowded train, for some reason, did not elicit negative feelings toward the other person. Possibly because the brain was not recognizing these impacts as an “attack” or “violence.” It was a very interesting mechanism where the repeated harmless collisions blurred the boundaries of personal space and reduced the psychological distance between each other.
Tsukahara, of contact Gonzo, giving instructions to the participants.
Next, Tsukahara divided the participants into 3 groups and instructed them to form a line with their eyes closed. This time, they were not allowed to collide with each other and had to rely only on the information of sound, such as using their voices or clapping their hands, to form a line. This resembled a simulated experience of echolocation which is the ability of animals such as dolphins and whales that use reverberating sound to recognize their surroundings.
Their movements were individualistic, with some actively walking around while others stayed still.
It was very difficult to move around while only relying on sound, and none of the groups were able to form a straight line. However, disregarding the visual and tactile sensations had activated the areas of my brain that were not normally used, which was refreshing and pleasant. I felt like contact Gonzo’s exercise that “causes glitches in the sensory perceptions” helped me recover from last night’s fatigue.
For the final challenge, everyone tried to form one line. In the end, we created a strange shape of one crowded group and 3 protruding lines.
2Lecture & Workshop"Bioinformatics" by Toshiaki Katayama
Learning bioinformatics, the technique for “reading” genomes
Shortly after 10 a.m. we finally began analyzing the genome data. On the stage were Toshiaki Katayama, project assistant professor at the Database Center for Life Science (DBCLS), and Mayumi Kamada, associate professor in the Department of Biomedical Data Intelligence, Graduate School of Medicine, Kyoto University. They explained about bioinformatics, which plays an important role in “reading” genomes.
Toshiaki Katayama (left), who, in addition to developing software for analyzing genome information, organizes the BioHackathon international conference, and Mayumi Kamada (right), who specializes in genomic medicine and medical big data analysis.
Bioinformatics is a new field that combines biology with informatics and is an academic discipline that uses computers to organize and analyze the vast amount of life-related data. Katayama is an expert in this field and has been involved with the development of “BioRuby,” a library for bioinformatics, as well as the extremotolerant tardigrade (Ramazzottius varieornatus) genome analysis project.
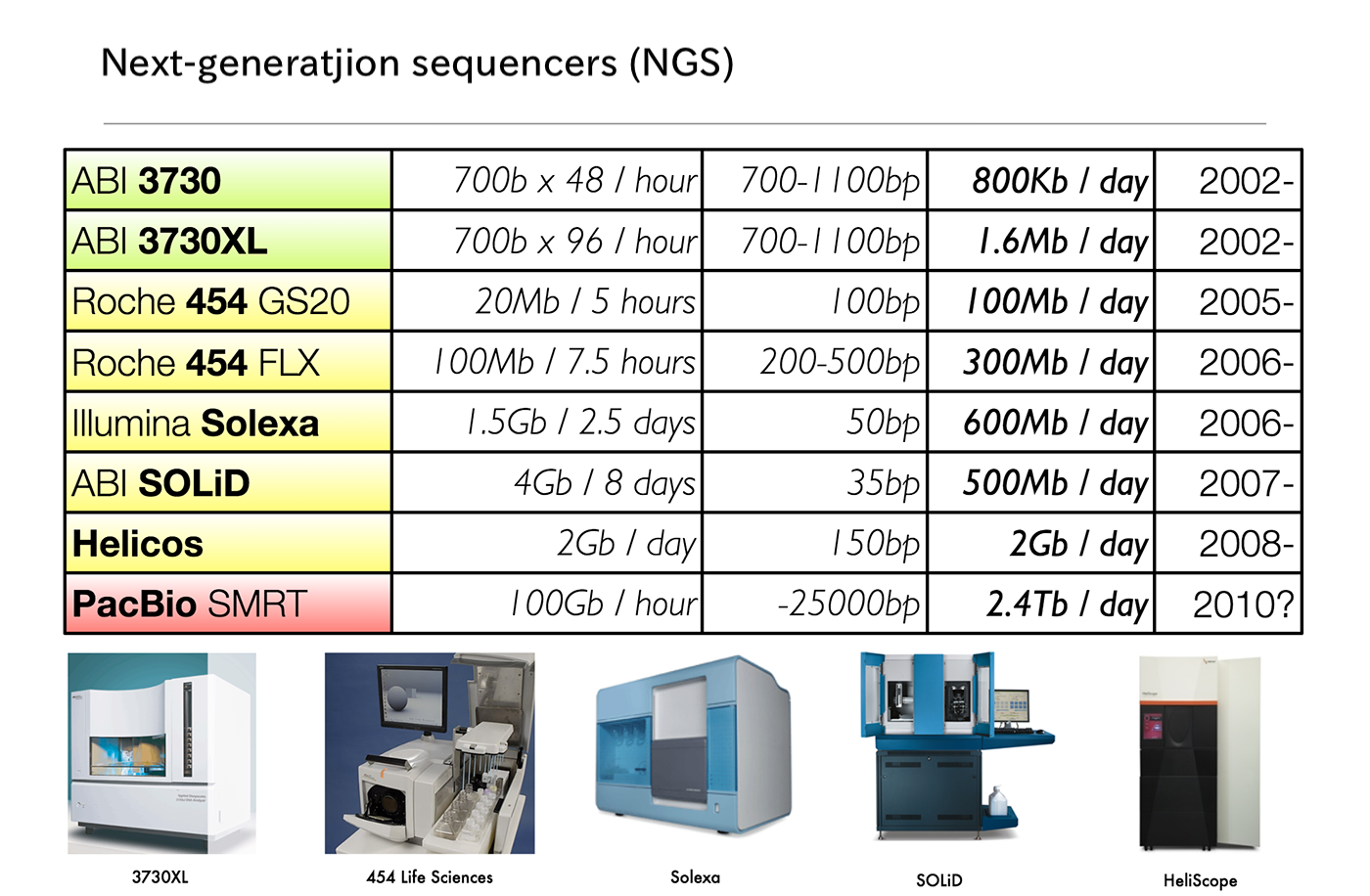
The background behind the emergence of bioinformatics was the “significant advancement of sequencers” explained Katayama. The first-generation sequencers (capillary type) came out in the 1990s and were used in the international Human Genome Project, but these cost a large amount of time and money because each sequence must be determined one at a time using electrophoresis.
“However, from the second half of the 2000s, next-generation sequencers (NGS) that could quickly decode base sequences became available. As a result, the genomes of various organisms have been sequenced and the acquired biological data has also been increasing rapidly” said Katayama.
In other words, bioinformatics was developed as a method for effectively processing and analyzing this data.
The processing capability of the next-generation sequencers continues to improve dramatically. Illumina based in the US and Roche based in Switzerland are known as the two largest manufactures.
“To determine a genome sequence, a large amount of sequence fragments that were read by the sequencer must be rearranged to their original order like a jigsaw puzzle (assembly). The base sequence data itself, however, is a random list of A’s, T’s, G’s, and C’s. For this reason, diverse analysis is required to understand what kind of genes there are and where they are located, if there are any communalities in the sequences of related species, and what kind of functions the proteins produced from the gene have.” explained Katayama.
The reference used for this analysis is the information recorded in the database called annotations. This is important information that accompanies the genomic data, and the newly determined annotations are continuously recorded in the database and play an important role as reference information.
Bioinformatics technology is also indispensable in creating this kind of database. Initially, the purpose of this database was for DNA sequencing and searching for genes, but currently the sequenced genomic information is also being used for analyzing the RNA transcribed from genes (transcriptome analysis) and for analyzing the sequences and functions of proteins which are the translated products (proteome analysis).
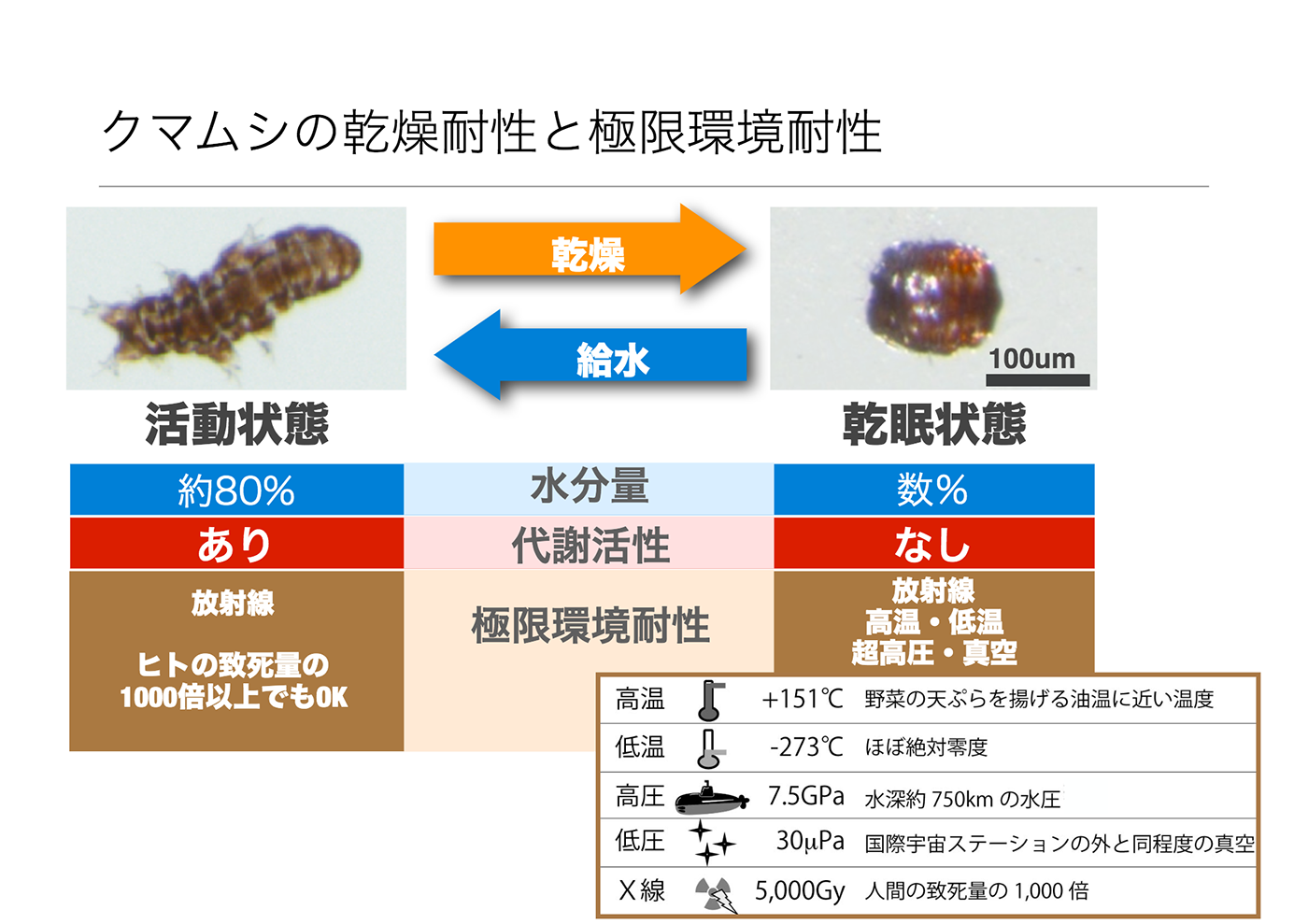
In fact, the extremotolerant tardigrade genome analysis project not only determined the genome sequence and identified genes, but also conducted transcriptome analysis to research the tardigrade’s ability to withstand extreme environments.
Tardigrades are organisms, about 0.5 to 1.0 mm in length, that live in various places around the world. In extremely dry conditions, they enter a state of suspended animation called cryptobiosis and they are known for their high resistance to ultralow temperatures nearly absolute zero, the vacuum state, and radiation.
Among all of the approaches that utilize bioinformatics, its application in medical science is particularly gaining a lot of attention.
“Genomic information is involved in a variety of genetic disorders. So, if we know the whole genome, we can learn about disorders caused by genomic abnormalities, such as chromosome abnormalities and genetic mutations. In addition, we can compare how normal cells and cancerous cells express genes (make proteins) and find out the mechanism that causes cells to become cancerous. Furthermore, efforts are being made to realize more personalized medical treatments (personalized medicine) by creating databases that link genomic information with disorders and clinical information.” (Katayama)
Toshiaki Katayama, project assistant professor at the Database Center for Life Science (DBCLS)
fter the Human Genome Project was completed, it was discovered that genome sequences varied among individuals (single nucleotide polymorphism) and that the genome could affect our physical constitution and proneness of becoming sick. In Europe and the US, databases that link genomic information with disorders and clinical information are promptly being created and are already proving useful for diagnosis and treatment in the medical field.
Katayama emphasized, “For that reason, creating a database specializing in Japanese genomic information as an information infrastructure is necessary for the progress of Japan’s genomic medicine.” He himself was involved with the development of TogoVar, a database that integrates genomic variations of the Japanese population, which was released in 2018.
Katayama then introduced Professor Soichi Ogishima of the Tohoku University Tohoku Medical Megabank Organization. Ogishima is one of the members who led the development project for the dbTMM database that integrates the whole genome information of approximately 3,500 Japanese people and the health survey information from cohort studies. This means that for this workshop we were directly assisted by Japan’s leading researchers in genome medical science. What a valuable opportunity!
Professor Soichi Ogishima (right) of the Tohoku Medical Megabank Organization, moving between tables to assist the analysis performed by participants.
Mapping the genome sequences read by the sequencer
The samples used for this workshop’s sequencing were the ingredients used in the Genome Bento (See the report for day 1). The Genome Bento was first created as a collaborative project between the BioHackathon team lead by Katayama and the YCAM members at an event held at YCAM in 2016.
The idea to make a bento using foods whose genome has been sequenced had first spread among genome-related researchers around 2005. At the time, however, there were very few foods whose genome had been sequenced. From the 2010s onward, the pace of genome sequencing for vegetables, grains, and meats began to pick up. There were finally enough ingredients to make it happen. In other words, Genome Bento is a project that was made possible owing to the advancement of sequencers.
For the second day of the workshop, the participants used the genome sequences read by the MinION sequencer and referenced the database to search which organism the genome originated from. The genome analysis workflow is as follows.
As mentioned in the report for day 1, the following 6 samples were used to “read” the genome.
(1) The whole genome has been completely sequenced with a high degree of accuracy (complete genome): Chinese cabbage, chickpea (2) The whole genome has been sequenced with some degree of accuracy (draft genome): Carrot, tomato (3) Cooked sample mixed with multiple ingredients: Ingredients of takikomi gohan, Japanese pickles
For samples (1), the whole genome was sequenced by using the DNA sample before PCR. These sequences were mapped (alignment) against the complete genome (reference sequence) to see if they were similar. For samples (2) and (3), the DNA samples that were obtained by amplifying the rbcL gene region using PCR were sequenced. Plant metabarcoding analysis was conducted on these sequences using DNA barcoding (A method that analyzes the sequences of specific gene regions to identify the species. Refer to the report for day 1).
Each team immediately checked the sequence results on the PCs. The base sequences read by the sequencer are called “reads” and the amount of these reads can be checked by using MinKNOW, the software that comes with MinION.
The Tomato team’s results. There are almost no long reads….?
The graph’s horizontal axis is the read length and the vertical axis is the total number of bases within a specific read length. In other words, this shows the distribution of the length and amount of reads that have been made. Only short reads were obtained because our team that read the tomato, in which I participated, sequenced the DNA sample that was made by amplifying a short particular region with PCR. As a result, the total amount of reads were 922.36 K (approx. 922 thousand reads) and the total number of sequenced bases (read length x number of reads) were 390.02 Mbp (approx. 3.9 million bases).
Using text data to check the read sequences
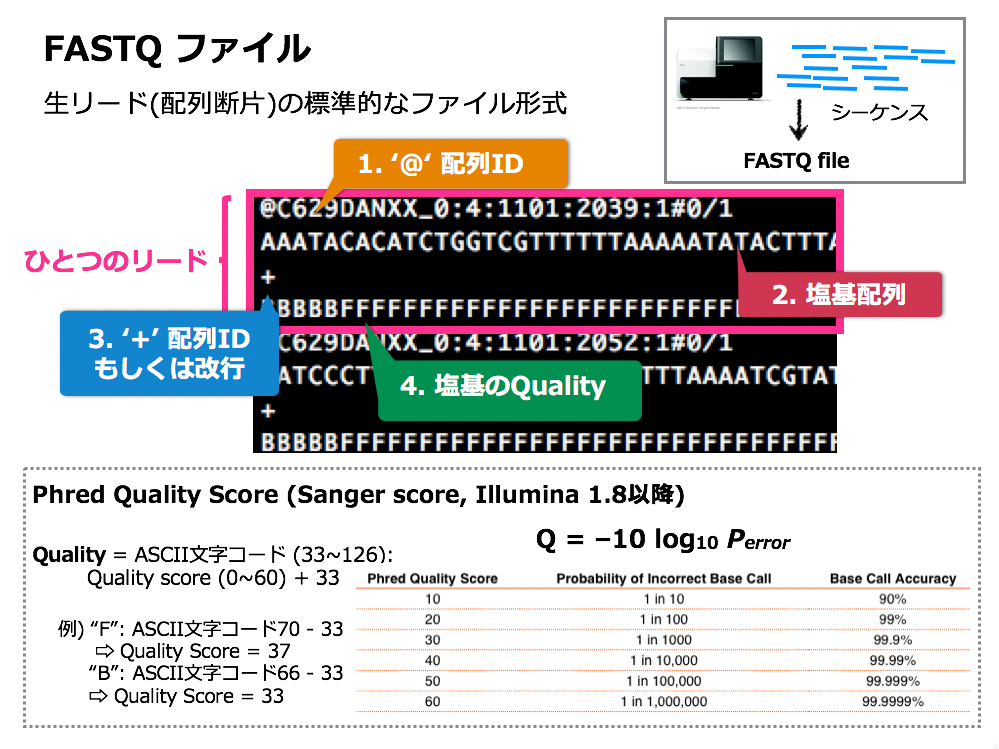
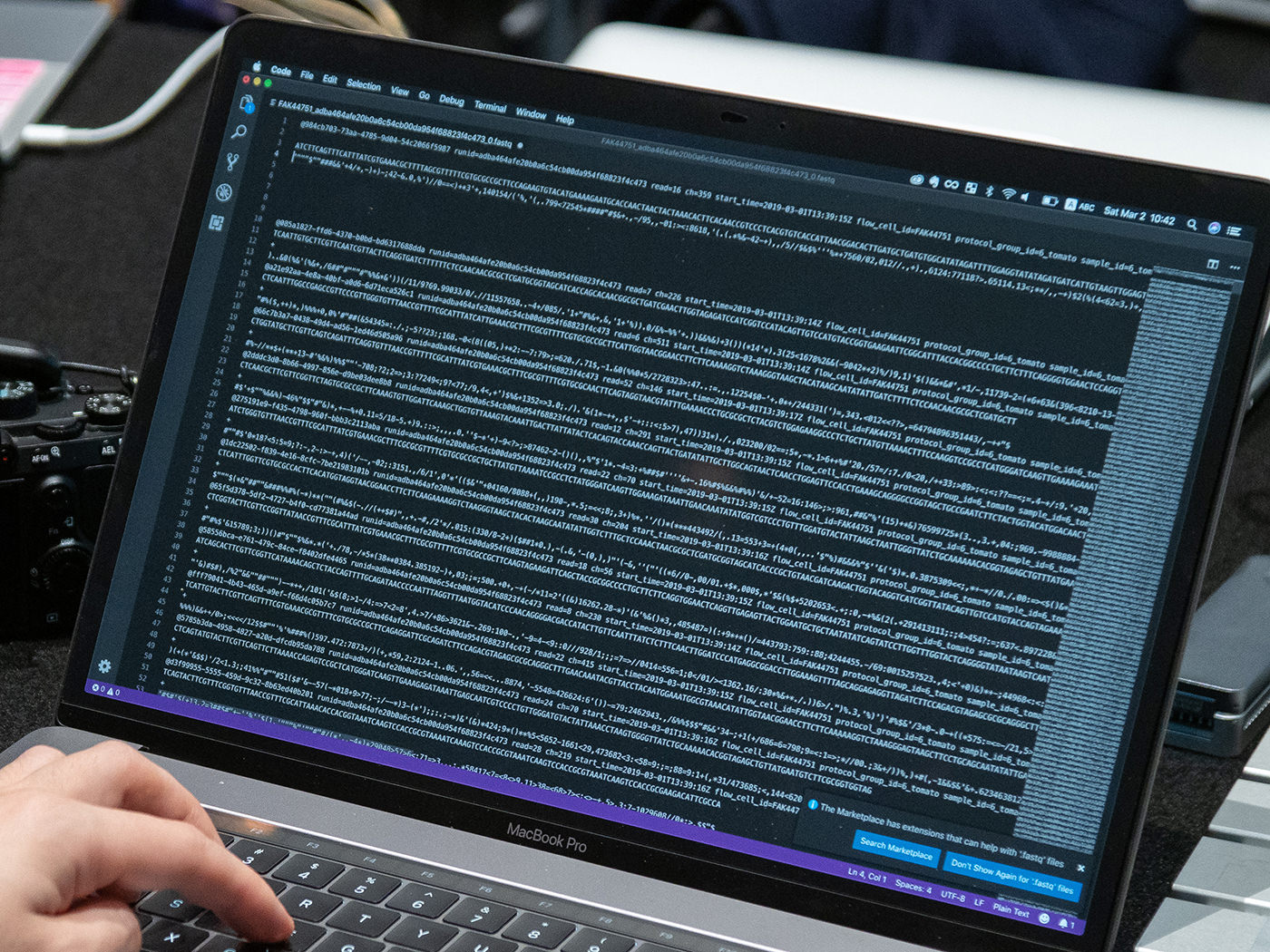
The read data for the 6 sequenced samples were already saved in a folder in the computer. The MinION read data is exported as a special file format called FAST5. At the same time, the software that comes with MinION automatically converts this into a text format data called FASTQ.
The FASTQ file that would be used for this workshop’s analysis is one of the representative file formats used during sequence data analysis. In the FASTQ file, each read data is written in 4 rows. The first row begins with @ followed by the sequence ID, the second line row is the read base sequence, the third row is the ID or line break, and the fourth row is the quality score.
The quality score is a number that shows the reliability of the read sequence and is assigned for each base. The reliability is purposely indicated along with the sequence because errors occur at a certain rate of probability during sequencing.
The quality score is calculated by using the error occurrence rate P in the conversion formula (see the figure above) to obtain the value Q. For example, if we assume the sequencer makes one sequencing mistake every 100 times, the error rate (P) is 1% (P = 0.01). In this case, the quality score (Q) is -10 x log10 (0.01) = 20. In other words, a quality score of 20 means the sequences was read with a reliability of 99%.
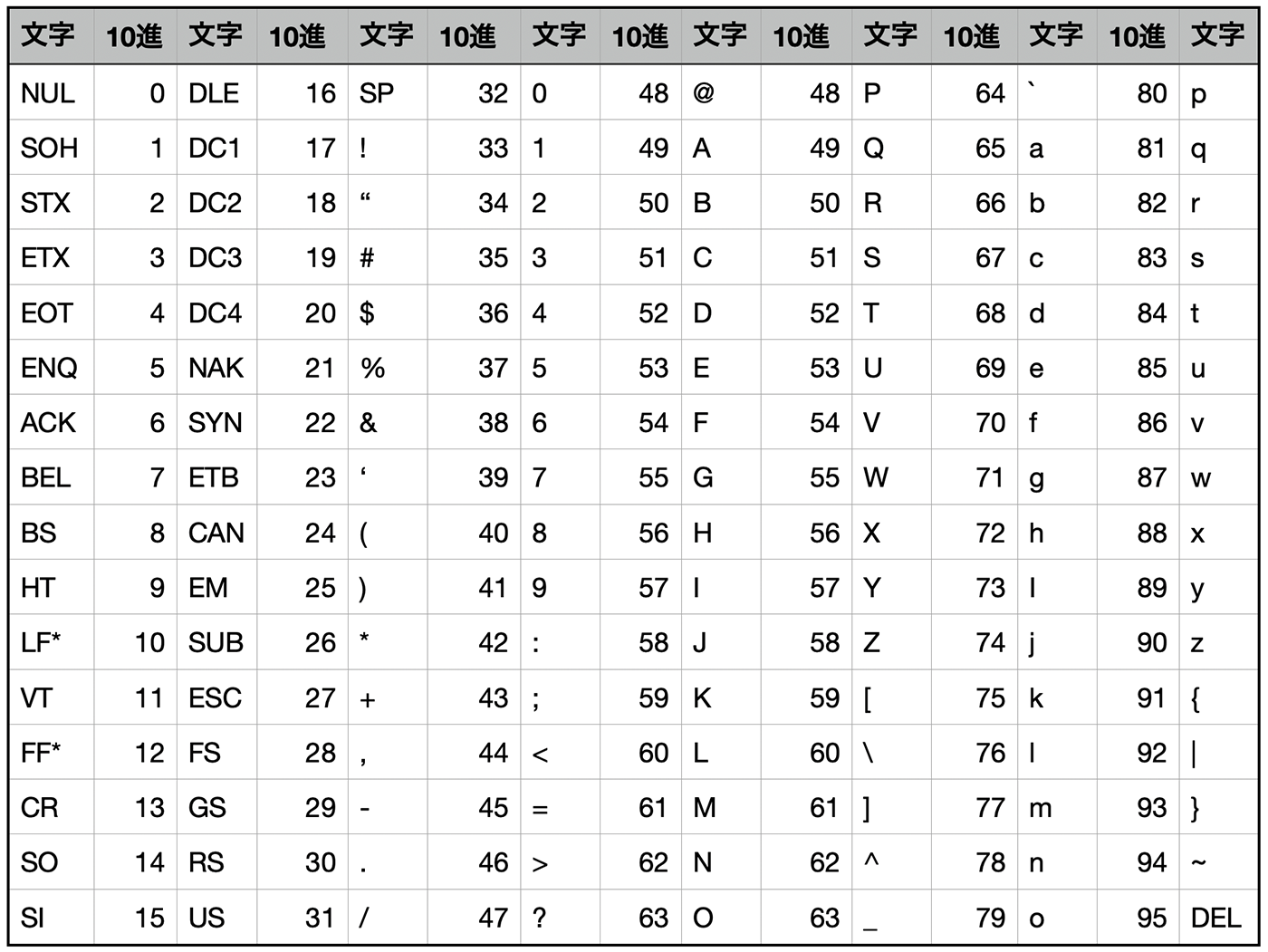
In addition, the quality score is written in ASCII code instead of normal text. ASCII code is a 7-bit character code made up of letters, numbers, and symbols that represent the integers from 0 to 127. This code is used in order to assign one character per base.
The ASCII code is made up of these letters, numbers, and symbols.
The depicted ASCII code represents a value which adds 33 to the quality score Q. For example, if the quality score in the FASTQ file’s read data is “F,” the decimal number that corresponds to F is 70, which makes the quality score Q 70 - 33 = 37.
Our tomato team also took a look at the readout FASTQ file.
This looked almost like a message from space and was incomprehensible for beginners.
A portion of the quality score from the fourth row of the first read looked like the following.
The quality score (Q) is proportional to the sequencing accuracy, so a read with a low Q value means that it was not read correctly. For example, if we back calculate the Q value of 1 by using the conversion formula, we get an error rate of approximately 79% (p≒0.79432), which means the sequence’s reliability is only about 21%.
Struggling with the extremely difficult read data analysis
Meanwhile, confused reactions could be heard from many other participants around the room. The work was a little too difficult for beginners unaccustomed to bioinformatics.
First of all, the current state of bioinformatics requires the use of Terminal on Mac or CUI on Linux. For people who do not have programming knowledge and who have only operated a computer using a mouse, the act of entering commands into Terminal itself seemed to be very hard.
Participants gathered around a PC with stern expressions on their faces.
In addition, since they were not able to completely understand the quality score’s complicated rules and how to interpret it just from a lecture of a few hours, all of the teams seemed to be having a difficult time. For this reason, Katayama, Kamada, and Ogishima along with the YCAM staff all came out to walk around the venue to provide support.
Kamada (back row, far right) going around each table explaining where the files are stored and their content.Participants listening to the advice from Katayama, who walked between the podium and the floor while giving explanations.Deciphering the read data while referring to the information Katayama shared on GitHub.
The tomato team was also confused.
“The quality score at each end of the read is mostly 1’s or 2’s.” “But as it goes to the right, the value gradually increases.” “When the score is 10, the reliability is 90%, but is this accuracy considered to be high or low?” “If there is one mistake every ten reads, then that must make a huge difference.”
While this discussion was going on, YCAM Director Ito appeared at our table and explained to us in detail.
“Normally, the quality score is low at the portions near the beginning and end of the read. But how a result with 90% reliability should be evaluated differs depending on the situation. For example, in the world of genomic medicine, the difference in just one base could affect the onset of a disorder, such as cancer or an incurable disease. In this case, the impact of a 10% reading error is large. For this reason, the same gene region is read repeatedly, and the results are overlapped to increase the sequencing accuracy.”
Arranging fragmented sequences in the correct order
In the next process the read sequence information in the FASTQ file is mapped (alignment) according to the sequenced complete genome data (reference sequence). Mapping is used to find out from which part of which chromosome of the reference sequence the fragmented read sequences originated from.
The FASTQ file records the sequence fragments in the order they were read. To check if the read was done correctly (If it matches the genome information of the sample food), the fragmented sequences must be correctly assembled according to the genomic coordinates. Mapping is similar to searching for the “addresses” of the read sequences.
The reference sequence was created using the optimal sequence data obtained from domestic and foreign public databases. Some of the DNA sequence databases are GenBank of the US National Center of Biotechnology Information (NCBI), ENA of the European Bioinformatics Institute (EMBL-EBI), and DDBJ run by the Japanese National Institute of Genetics (NIG). These databases are linked together so that whenever new information is registered to one of the databases, it is automatically shared with and reflected in the other databases. Therefore, they play an important role as an international information platform for the field of life sciences.
For this workshop, Katayama and others had already created the optimal reference sequence and placed it in a folder. The sequence data is stored in a file format called FASTA that does not include the quality score. If you would like to try creating a reference sequence on your own, please refer to the detailed process documented on Katayama’s GitHub. https://github.com/ktym/GenomeBento/ (Japanese language only)
For mapping, a tool called Burrows-Wheeler Alignment (BWA) was used. Though BWA is a program that has been used for mapping short reads under 200 bases, the subcommand “bwa mem” which is an algorithm for longer reads (70bp to 1Mbp) is also implemented. For this workshop, the PCs were already installed with BWA, but if you would like to do mapping on your own computer, you will need to download and install the program from the dedicated website.
The mapping was done using the read data of the ingredients whose whole genome had been completely sequenced (1) (Chinese cabbage, chickpea). The remaining 4 teams that selected the ingredients of (2) and (3) also tried mapping by selecting either Chinese cabbage or chickpea. Our tomato team decided to use the read data of Chinese cabbage.
This time, The MinION was set to output one FASTQ file for every 4,000 reads. Thus, the read data that was divided and saved to multiple files needed to be combined into one FASTQ file before beginning the mapping. In preparation, the cat command in Terminal was used to merge the multiple files into one.
Next, the BWA command was used to create an index for the reference sequence file (This time, this was already made by Katayama). This index was used to execute the mapping algorithm “bwa mem” to map the merged FASTQ file of Chinese cabbage (or chickpea) to the respective reference sequences.
Around the room, however, people were having difficulty understanding the complicated mapping mechanism and BWA commands, and there were several teams that got stuck in the process. The tomato team was finally able to successfully execute the BWA commands thanks to the efforts made by Kosei Ikeda, an engineer participating from Kyoto, and Jun Fujiwara participating from Tokyo. The mapping itself completed in just 15 seconds.
Ikeda (front right) and Fujiwara (front left) who led the analysis work for the tomato team.
The mapping results were saved in a file format called SAM. The SAM file describes to which sequence of which chromosome each read sequence was mapped. A compressed SAM file is called a BAM file.
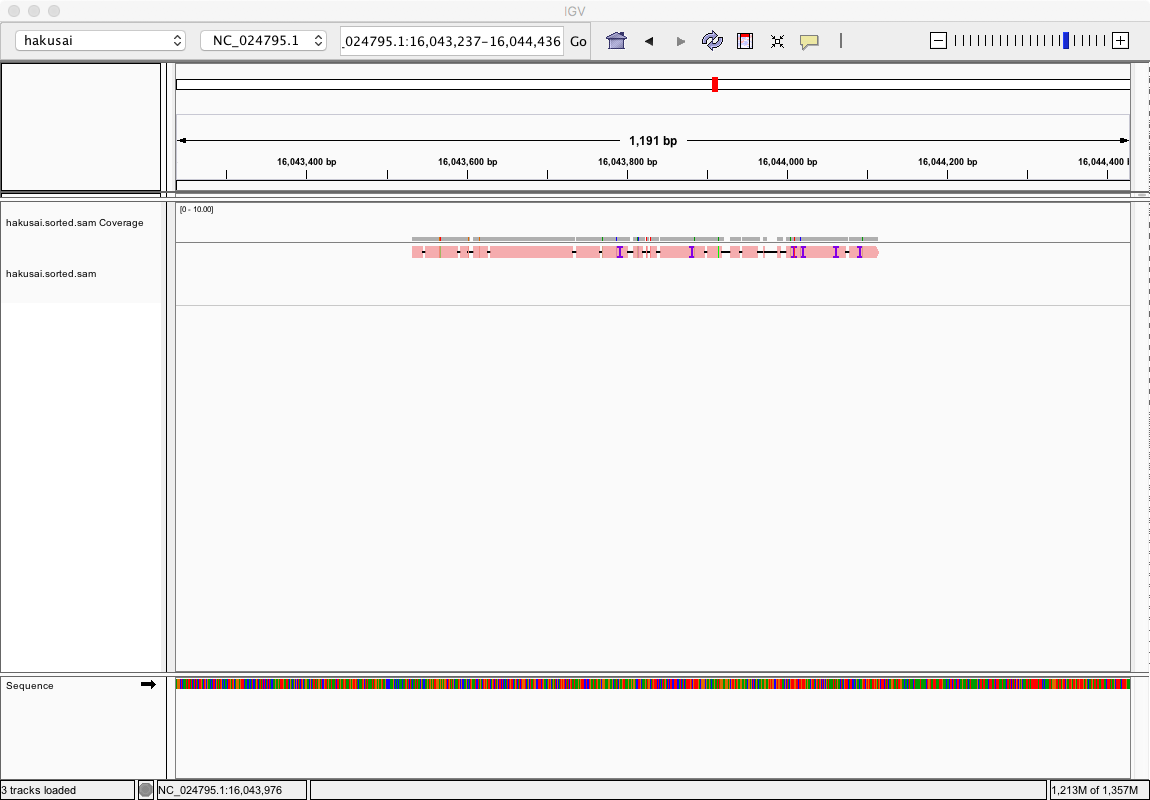
To check the mapping results in the SAM file, a genome browser must be used to visualize the contents. The genome browser is a tool for visualizing the information that accompanies the genome (annotation) and describes the sequence information or the position of a gene. This time we used a genome browser called IGV.
We opened IGV, which was installed in the PCs for each team, and loaded the reference sequence (The FASTA file was converted into a format that can be used in IGV. The extension was .genome) of the selected ingredients (Chinese cabbage or chickpea). If the DNA sequence for each chromosome can be selected from the pulldown menu, it is proof the file was loaded correctly.
Next, we used the tools (igvtools) in IGV to sort the SAM file we made in the order of the genomic coordinates. This is because the SAM file’s read information is recorded in the order they were sequenced and not in order of the genomic coordinates. The sorted SAM file was saved in a file with the .sorted.sam extension.
Lastly, we loaded the .sorted.sam file to IGV to see the mapping results. We could freely zoom into any location on the browser to visually check where the read fragments were mapped to the reference sequence.
The read fragments that matched the reference sequence are shown in red.
We searched for the mapped reads by repeatedly zooming and scrolling while referencing the SAM file’s genomic coordinates, and finally found what looked like the correct location.
“Hey, there it is!” “It’s cute!” “There’s one here too! It looks like a lot were mapped.”
Such happy expressions could be heard from each table. When it was confirmed that the reads were properly mapped, enthusiastic applause erupted throughout the room.
Participants impulsively taking pictures of the IGV screen when the mapping was successful.
Attempting plant metabarcoding analysis to identify the plant species
Next, we used the rbcL genes from samples (2) (carrot, tomato) whose whole genome sequence had been partially sequenced and the samples mixed with multiple ingredients (3) (Ingredients of takikomi gohan, Japanese pickles) to attempted plant metabarcoding analysis. rbcL is a gene in the chloroplast genome, and since it often differs by plant species, it is used as one of the DNA barcodes for identifying plant species.
The basic protocol is the same as mapping the reads as mentioned above. The read data (FASTQ file) of the rbcL gene region amplified by PCR is mapped to the reference sequence by using the BWA commands and creating the SAM file. A special database was used for the reference sequence and was prepared in advance by Katayama and others based on the rbcL gene sequence data set collected from 87,000 species of plants described in the following academic paper.
“An rbcL reference library to aid in the identification of plant species mixtures by DNA metabarcoding.” Bell KL, Loeffler VM, Brosi BJ. Appl Plant Sci. 2017 Mar 10;5(3). pii: apps.1600110. doi: 10.3732/apps.1600110. eCollection 2017 Mar. https://www.ncbi.nlm.nih.gov/pubmed/28337390
It would be considered a success if the reads are mapped to the rbcL reference sequence of the same plant species. This time, instead of the genome browser, a simple script (check.sh), prepared by Katayama and others, was used to verify the contents of the SAM file.
check.sh counts the number of reads mapped to the reference sequence for each plant species based on the SAM file data. By using a command in Terminal, the results were sorted in the order of the most similar sequences.
“Tomato” was not in the search results for similar sequences…
For the tomato team’s results, the most similar sequences were “potato” (749 matches out of all of the reads). As we scrolled to the bottom of the results, we did not even see the “t” for tomato. As the team started to feel disappointed, Katayama came to the rescue.
“Both potatoes and tomatoes belong to the Solanaceae family, so they are close. And the ‘Solanum lycopersicum’ shown at the top of the results is the scientific name for tomato, so it appears the reading went pretty well.”
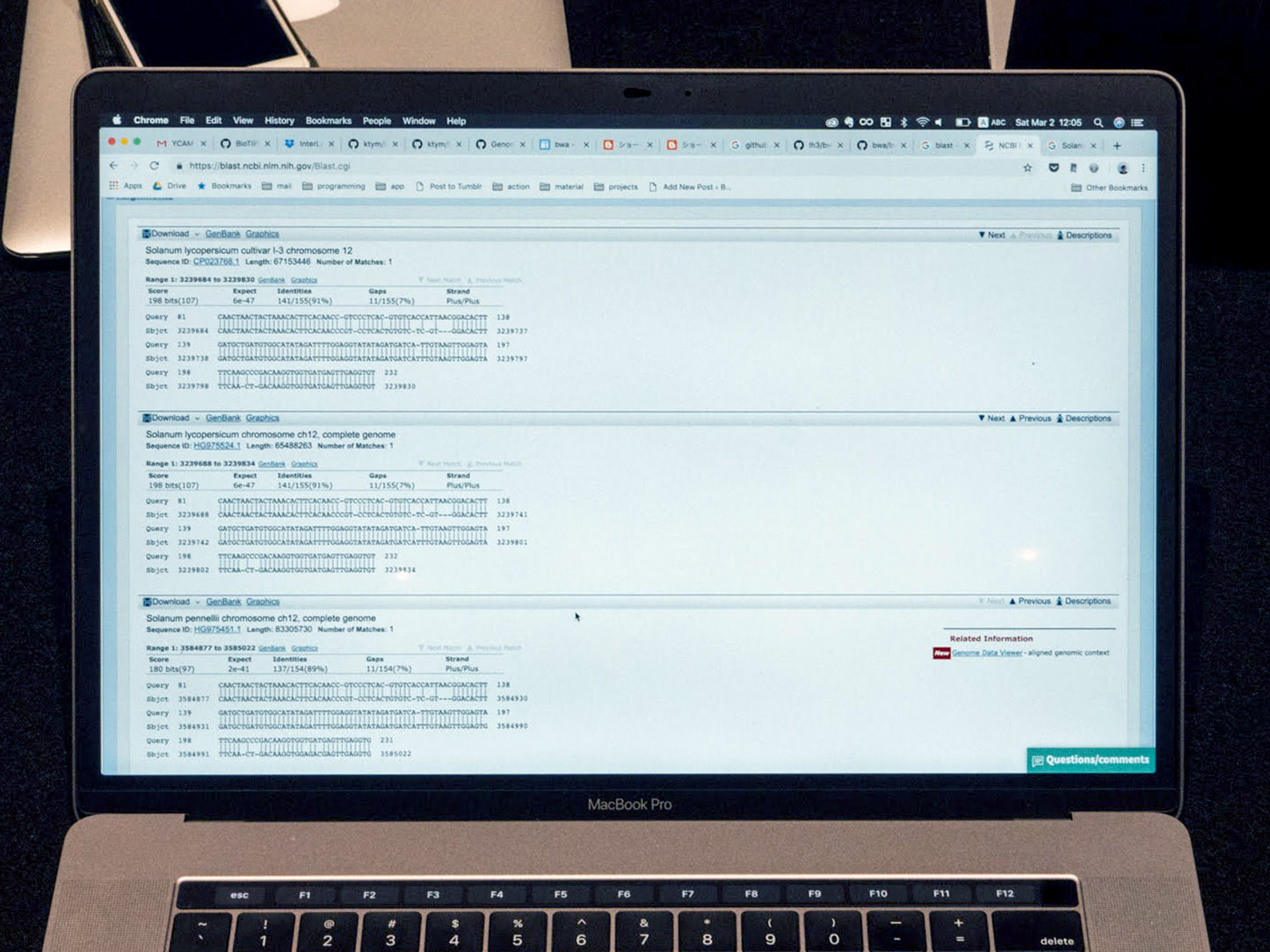
When the whole analysis had completed, Katayama introduced a web browser tool that can search for sequence homology. The Basic Logical Alignment Search Tool (BLAST) managed by NCBI is a convenient tool that searches and collects sequences from the database that are similar to the query sequence data. https://blast.ncbi.nlm.nih.gov/Blast.cgi
On the BLAST site, the query sequence is either directly entered into the text box or uploaded as a FASTA file. When the “BLAST” button is pressed, the site shows a list of species with similar sequences. We tried copying a part of the tomato’s read sequence from the FASTQ file and searching it on BLAST, and it showed 3 results. We were able to confirm that our read sequence was similar to sequences that all had scientific names for tomato.
When mapping with BWA, the result was “potato,” but with NCBI BLAST the probability of “tomato” increased.
If there are convenient tools like NCBI BLAST, it seems unnecessary to go through the trouble of entering commands. However, since analyzing a large amount of read data on a browser is a great burden for the system, for this workshop, the analysis was conducted using a database that was created locally.
Experiencing the impact of the dawn of personal biotechnology at first hand
Our experience with genome mapping and plant metabarcoding analysis was only the very beginning of genome analysis. In actual practice, the reads mapped at this stage are the starting point for analyzing which genes they correspond to, or finding out if there are any variations by closely comparing them to the reference sequence.
After the exercise, I asked the participants of our team about their impressions and there were various opinions.
“To promote the spread of personal biotechnology going forward, a user interface that can be intuitively used by anyone, and can handle the whole process from FASTQ files to mapping must be developed. My impression is that, currently, it’s difficult to use without knowing programming.” (Ikeda, engineer mentioned above)
“The current state of biotechnology can be compared to the MS-DOS age of computers. Just as Windows eventually became available in the realm of PCs, I think many convenient tools will also begin to appear in the field of biotechnology.” (Masato Takemura, representative of FabLab Hamamatsu/TAKE-SPACE)
In the 1970s there were many people who went through a lot of trial and error with the newly available 8-bit microprocessors in their garages and backyards. Their curiosity and enthusiasm resulted in a huge movement that led to the popularization of personal computers. At this workshop, the scene of people with different backgrounds coming together to struggle with this new field called biotechnology looked as if they were re-experiencing the excitement and thrill during the dawn of the personal computer. I felt very fortunate to witness personal biotechnology at first hand as it began to unfold.
This may one day become one of the important scenes in the dawn of personal biotechnology.
Genome Bento being realized by the advancement of next-generation sequencers
After the genome analysis exercise, it was lunch time. The second day’s Genome Bento was also prepared by Vegetable Cafe ToyToy. This time, it was the real Genome Bento made by only using ingredients and seasoning whose genomes have been sequenced. It included ingredients that we had just sequenced such as Japanese pickles made with Chinese cabbage and takikomi gohan! I enjoyed each dish while imaging the base sequences of A’s, T’s, G’s, and C’s.
There were salmon and Chinese cabbage penne, cabbage and bok choy salad, miso baked chicken, and stir-fried vermicelli and pork. I was moved by the fact that this colorful bento would not have been possible without the advancement of sequencers.
According to Atsushi Murata of Vegetable Cafe ToyToy, who was in charge of making the bento, the ingredients used in the Genome Bento were selected from this database. New ingredients are added to this database as needed by Katayama and others who search academic papers to check for information about the latest sequenced genome. Murata said, “If ginger and garlic are added, it will greatly widen the range of flavoring, so I’m looking forward to those ingredients being sequenced as soon as possible.”
Katayama said, “It’s because of ToyToy that such a delicious bento could be made from such a limited selection of ingredients.”
During the afternoon session Tsuda of YCAM gave a presentation on “writing” genomes. The “writing” workshop proceeded mainly with lectures rather than practical exercises.
“‘Writing’ genomes is equivalent to the field of synthetic biology. This academic discipline combines the concepts of conventional biology with engineering.” (Tsuda)
Tsuda of YCAM gave another presentation following Day 1
Synthetic biology follows the engineering cycle of design, build, and test to gain a deeper understanding of life by creating new biological systems. A wide range of research is being conducted by applying technologies such as conventional gene delivery and genome editing.
“A typical example is to give cells a targeted function by inserting the designed DNA into circular DNA called plasmids, introducing the plasmid into E. coli or yeast, and culturing a large quantity of cells to amplify the subject DNA. This technology is used in applied research, such as making E. coli produce biofuel or pharmaceutical ingredients, or sense toxic substances.” (Tsuda)
Recently, progress has been made in research for creating life itself. In 2016, synthetic living bacteria with a minimum genome (minimal cell) was announced and drew much attention. With this development, a global competition for promoting the advancement of synthetic biology has been annually held. This is the International Genetically Engineered Machine (iGEM) competition mentioned by Philipp Boeing on day 1.
“At iGEM, the participating teams compete by using a combination of standardized DNA parts (BioBricks) to create new biological systems. In addition, iGEM places great importance on the biosafety and bioethics surrounding synthetic biology and is managed under strict rules.” (Tsuda)
Tsuda also mentioned the book (Japanese translation of “BioBuilder—Synthetic Biology in the Lab”) that was published in November 2018 and for which he supervised the translation. This book was written based on the framework of iGEM and is an introductory book that covers topics from the basics of synthetic biology to experiment protocols and bioethics. This book is a must-read for anyone wanting to engage in DIY bio.
Japanese translation of “BioBuilder—Synthetic Biology in the Lab” (O’Reilly Japan, published November 2018)
4Talk“Small Thoughtful Science” by Sebastian Cocioba
Talk by Sebastian Cocioba who modifies plants
The following lecture was given by Sebastian Cocioba who is a DIY biologist and molecular florist based in New York, USA.
After studying biology in college, Cocioba dropped out of school and since then had studied genetic engineering and synthetic biology on his own. He currently manages the research group Binomica Labs together with other volunteers engaged in DIY bio. While continuing research mainly on plants (flowers), he is active as an evangelist for DIY bio, by publishing his research as open source and holding workshops for the public.
As a child Cocioba was fascinated by the beautiful flowers and plants and “wanted to learn the secrets of plant evolution,” which is why he became involved in DIY bio.
His lab is located at the corner of his mother’s apartment from where he can see the Manhattan skyline. He renovated one of the bedrooms and gathered the necessary equipment himself. He says his lab meets the US biosafety level 1 (BSL1) standards. The biosafety level is the safety standard defined by each country that follows the guidelines of the World Health Organization (WHO) for laboratories that handle bacteria and viruses. Cocioba has been conducting research for 15 years while living with his mother in a house with a bio lab.
Picture of the bio lab at a corner of his house.
Cocioba first introduced his research for sequencing the DNA of oxalis as one of the “reading” projects he conducts in his lab.
Oxalis stricta is a weed that grows everywhere around the world, and Cocioba noticed that it had various sizes and colors in each region. How can a single plant exist in so many places and be so genetically diverse, yet be the same species? He thought that if he researched the different morphology in each region, he could learn the secrets behind its evolution.
Oxalis is called Katabami in Japan and can be easily found in gardens and roadsides.
During the research process, a 12-year-old girl made a remarkable achievement. When she was 10 years old, she attended a workshop held by Cocioba, where she began to wonder about the nutritional source required by oxalis and began researching its ecology.
She experimented the growth conditions of 100 oxalis plants using fertilizers made of 5 components at different concentrations and conducted this three times. She recorded in detail the number of leaves and the amount of water in each plant, while also installing a camera to take time lapse photographs. She posted it every day on Twitter. Cocioba taught her the statistics to use on the data she obtained, and she conducted the analysis herself.
She presented her research results at a science fair and won first place. This 12-year-old girl was the first in the world to identify the nutritional needs of oxalis stricta.
The new findings on nutrition obtained from her experiment contributed greatly to the oxalis DNA sequencing project led by Cocioba. Later on, Cocioba’s research team used a MinION to conduct sequencing and obtained 500 million reads, about 200 thousand of which were 2 million base pairs per read.
Even amateurs without specialized knowledge or academic degrees can conduct world-class research at a personal lab. Their case is a great example that shows DIY bio’s potential for accelerating innovation.
Cocioba’s “writing” project
Cocioba also introduced his “writing” project in which he is attempting to create a blue strawberry. As he showed a photo of the popular blue rose developed by Suntory, he pointed out that the color was not blue. He said that he wanted to develop a plant that anyone would perceive as blue with a strawberry rather than a rose.
It would be like the fictional strawberry (Snozzberry) that appears in Charlie and the Chocolate Factory.
Cocioba said that he wanted to make a plant that anyone would say is “blue.”
According to Cocioba, there are 12 types of proteins which express the color blue that can be found in the ocean. Among those proteins, he focused on a protein found in clams that inhabit tropical areas.
By inserting a gene that produces that protein into bacteria and cultured it for 37 generations, he was recently successful in culturing bacteria that express the blue protein.
Then, he inserted the gene into agrobacterium, which is a type of soil bacteria. Agrobacterium have the ability to introduce their genes into plants by infecting them and are often used as a gene carrier (vector). In other words, it is possible to create blue flowers or fruit by inserting the gene that expresses the blue protein into the agrobacterium, and then using it to introduce the gene into the target plant.
The blue protein extracted from the transgenic bacteria. He named it “Bino Blue (Binomica Blue).”
Since he has obtained the DNA for creating the blue protein, he will transform a petunia plant with the agrobacterium to make it bloom blue flowers. After he establishes a method for stably expressing blue protein in plants, he plans to attempt his main objective of developing the blue snozzberry.
Cocioba continued to introduce the Infinite Discovery Machine, which he said was a somewhat conceptual project.
All living organisms pass on proteins to the next generation and evolve through repeated natural selection. This means that proteins are expressed according to the order created in the process of evolution. But does it mean that proteins that are generated “by chance” from random DNA in nature does not exist? This project began with that simple question.
Cocioba and his team first created a program that produces proteins from random sequences of DNA and ran a simulation that compares those sequences with the known proteins on earth. Then, they tried to evaluate whether the proteins would be toxic or hazardous if they were actually expressed.
The result was that the proteins created ‘by chance’ did not resemble any proteins found in nature and their toxicity and hazardousness remains to be unknown. In other words, “we don’t know what we don’t know”, because it is impossible to analyze something that does not exist on earth and is unknown. However, even for such mysterious proteins, if their genes are introduced into bacteria, they could be expressed. This is a very gray area from the perspective of bioethics.
Cocioba and his team continued experimenting while taking heed of the ethical issues. First, they isolated the oxalis DNA and used enzymes to cut the DNA into single bases. They then used DNA ligase, which functions as the glue that bonds bases of DNA to each other, to randomly connect the bases. Then, to insert this DNA strand into a plasmid, they recut the ligated sequences by using a restriction enzyme that only cuts specific sequences. By inserting these fragments into plasmids and introducing them into bacteria, they were successful in expressing randomly generated proteins that do not exist on earth.
They analyzed the produced proteins using a free structure analysis tool and determined that the structures do not resemble any proteins that exist on earth. Not only does this discovery have unlimited possibilities, such as using them as catalysts or for discovering new drugs, but it also has major ethical issues. What kind of effects would there be if a non-existent protein interacts with an existing organism? Cocioba asked bioethicists their opinions on how they should proceed.
However, according to Cocioba, one of their replies was, “There’s no way to know until you do it”. It’s not beyond the realm of possibility that these unknown proteins might threaten agriculture or human life. Cocioba has been continuing this project while being completely open to the public in order to perform careful risk assessments of the effects of his research. All of the data set related to the research has been published as open source and can be accessed by anyone.
Just as Cocioba and his team continues to conduct research in a room in his mother’s apartment, today is the age when anyone can become a scientist. The world of DIY bio is producing not only conceptual projects but also many projects that are useful for society. There is no doubt that Cocioba will continue contributing to the advancement in science through DIY bio.
5TalkBioart and DIY Bio: Alternative explorations of life by Hideo Iwasaki
A talk by Hideo Iwasaki on understanding the significance of bioethics and bio art
The presentation by Cocioba was followed by Professor Hideo Iwasaki of the Department of Electrical Engineering and Bioscience, Waseda University. Iwasaki conducts research on a type of photosynthetic bacteria called cyanobacteria, and is also a bio artist.
Hideo Iwasaki, professor of the Department of Electrical Engineering and Bioscience, Waseda University. He also leads the bioaesthetics platform, metaPhorest.
He first laid out the bioethical issues and regulations that are indispensable for considering the application potentialities of DIY bio (personal biotechnology) from various perspectives.
The most important matter for DIY bio is safety. Iwasaki emphasized that, “It’s necessary to give the utmost consideration to prevent the disturbance of ecosystems and the side effects for humans.”
“We don’t know what kind of effects there would be on the ecosystem or humans if a genetically modified organism leaves the lab. It was none other than the scientists themselves that were the first ones to predict this risk and put the brakes on its use. As soon as recombinant DNA technology emerged in 1973, they quickly created rules for conducting research safely. The international conference held in 1975 had a major impact on the laws and guidelines stipulated for research involving genetic modification in each country.”
In response to this, in 1979, the Ministry of Education and the Science and Technology Agency of Japan at the time also established the Guidelines for Recombinant DNA Experiments. Thereafter, the Act on the Conservation and Sustainable Use of Biological Diversity through Regulations on the Use of Living Modified Organisms became effective in 2004, thus elevating the guideline to a law. This is commonly known as the Cartagena Act and also establishes clear penalties. Currently, if an enterprise or university conducts experiments involving genetic modification, they must observe the Cartagena Act and have the details of their experiment examined in advance and approved by the related government agencies.
From Iwazaki ‘s presentation materials
As the second issue regarding bioethics, Iwasaki pointed out the state of these rules and regulations. The reason for this is that in recent years the development of the laws have not kept up with the advancement of technology. Therefore, cases in the gray area that are not covered by the law are increasing.
“For example, in the case of genome editing technology, there are cases that do not conflict with the current Cartagena Act, such as base substitutions that can also occur in nature. In addition, there is a possibility that the regulations would not apply to cases where individuals introduce genes, that they had prepared, into their own body. If such gray areas expand, it will also raise problems of the uncertainty of where the responsibility lies. How can we achieve a balance between the openness of biotechnology and responsibility? This is a major issue in the advancement of DIY bio.”
Iwasaki discussing the “great importance of knowing how bioethical rules have been made.”
In addition, Iwasaki also touched on the issues relating to information and the media. Since DIY bio does not have a practice like academia where research results are written in academic papers and are then published in a format that can be verified, the insufficient disclosure of information and the risk of incorporating fake information are often pointed out. Iwasaki emphasized that, “The major problem is when speculations and facts are mixed together and assessments become difficult to make.”
“As long as life and the human body are being handled as the subject, social responsibility will come along with it. Even if it is speculative artwork, it should be viable for fact-checks and third-party verification. This is the minimum literacy that people involved in DIY bio should acquire.”
Iwasaki explaining the various perspectives regarding life.
Thus, there are still many ethical issues regarding DIY bio that need to be considered. However, DIY bio also has a great potential. While the greatest expectation is placed on the bottom-up innovations in fields such as medicine, Iwasaki suggested that, “Importance should also be placed on the inherent cultural value of DIY which is unconstrained by the context of industries or businesses.”
“Originally the DIY culture is about making something with your own hands and being creative to enhance your life. Biotechnology is one of the means for doing this and is not the objective. If you actually try DIY bio, it’s difficult to obtain the expected results, and you’ll soon realize that handling the DNA of organisms is not that easy. However, I think there is greater value in questioning and understanding the essence of life and your own existence through that process of trial and error.”
Iwasaki himself built a bio lab in the atelier of his home in 2012 to practice DIY bio. In 2014, he observed a phenomenon where the cyanobacteria he had cultured formed a colony which created a vortex pattern as it transitioned. He said it might have been witnessed for the first time in the world.
The bio lab built by Iwasaki. He purchased most of the equipment from auction sites.
“When observing a group of living organisms, you can often see the phenomenon of individual organisms that at first were randomly moving, gradually align their movements with those around them and begin to move in the same direction to form patterns and structures in spontaneous order. The contact Gonzo workshop held this morning also reminded me of this phenomenon. Currently, this type of phenomenon is being analyzed using mathematical models in a continued effort to understand the order formation mechanism of living organisms. It’s important that this kind of discovery can be done at home using a low-tech microscope. I think, that is truly the greatest potential of DIY bio.”
Comprehending life from the perspectives of both science and art
In conclusion, Iwasaki spoke about the application of DIY bio to art and its significance. As introduced at the beginning, while he continues his research on “life” as a biologist, he is also exploring “life” as a bio artist. Since 2007, he has led the metaPhorest platform for aesthetic research and production regarding life. He has created an open space for shedding light on the question of “What is life?” and researching from the perspective of not only life science but also humanities.
Currently, the group consists of about 10 members with various backgrounds, such as researchers, artists, and designers.
Iwasaki said, the reason he is approaching life from the perspectives of both art and science is “to join the life that is the subject of science with the life we talk about in our daily lives.”
“In natural science, life is viewed as an observable phenomenon that exists within the research subject. Art or philosophy on the other hand perceives life as an experience that exists in relation to the observer. Science has been avoiding such an emotional view of life by all means. In other words, if we only viewed life from the perspective of science, other perspectives of live will most likely be disregarded. How can we associate life that is considered as a phenomenon by science with the sense of “life” we have? When questioning this, I thought it would be effective to use art as a framework for talking about this.”
The respective views of life by science and art appear to be binary opposites. However, actually “they are in a relationship that is mutually inclusive like that of a Mobius loop” explained Iwasaki.
“Thinking about life overlaps with the question of how we should navigate this Mobius loop. The attitude of thinking about life and trying to understand it while going back and forth among various perspectives of life is essential. For me, bio art is a platform for doing this.”
Many ambitious bio artworks have been created at metaPhorest.
Iwasaki introduced some of the bio art projects he has been involved in. One of which is the “Culturing ‘Paper’cut” presented in 2013. This work was based on the concept of having the scientific paper on cyanobacteria be hacked by the bacteria, that are the observed subject themselves, to reverse its position.
“Though scientific papers pursue objectivity, biological papers often contain many subjective statements. Based on this, a research paper, from which subjective phrases were cut out, was placed on culture media and the cut out sections were inoculated with cyanobacteria. The slowly growing bacteria surpassed the scientists’ subjectivity while generatively forming new patterns. This work intends to associate the scientific act with the artistic expression like a Mobius loop.”
Hideo Iwasaki “Culturing ‘Paper’cut” (2013-)
Another work was “aPrayer: memorial service for artificial cells and lives,” that was exhibited at KENPOKU ART 2016, an art festival held in Ibaraki. When cells are artificially synthesized to carry out biological functions, do we recognize them as one “life”? This was an experiment to reconsider the lifeness of artificial cells through the ceremony of a memorial service.
“The act of holding a memorial service is the ultimate form of an emotional view of life and is also the complete opposite of the view of life defined by natural science. To make this artwork, the ‘remains’ of artificial cells from more than 10 artificial cell researchers were collected and placed in a glass urn. With the cooperation of the local people, we placed a stone monument for the burial and held a memorial service.”
Hideo Iwasaki + metaPhorest “Artificial Cells + Stone Monument for Artificial Life ” from “aPrayer: memorial service for artificial cells and lives” (2016)
During this process, they also interviewed the artificial cell researchers. The researchers’ remarks revealed their views of life that swayed between their rational and emotional thoughts, which Iwasaki said, “Allowed me to get very interesting statements.”
“One of the researchers suggested that artificial cells which could be reproduced at any time couldn’t die in the first place. In other words, even if we can create life, we cannot create death. That is a very important perspective, but in light of scientific norms, such considerations are disregarded. I believe that bio art will play the role of considering and visualizing such diverse views of life that float unconsciously in our minds.”
Bioart and DIY Bio: Alternative explorations of life by Hideo Iwasaki
Learning the method of organizing our thoughts and verbalizing them precisely
After gaining new perspectives regarding life from Iwasaki, a workshop was held by Daiya Aida. Aida, who was also the curator for Aichi Triennale held from August to October 2019, had worked as a museum educator at YCAM for 11 years since its opening in 2003. He has a career in developing numerous unique workshops. What he prepared this time was an exercise for organizing your thoughts and verbalizing them precisely.
In addition to developing original workshops and educational content, Daiya Aida is also a curator.
“Ethical judgments regarding DIY bio are meant to change depending on the societal conditions, era, and culture. In order to have meaningful discussions about a subject that doesn’t have absolute answers, such as in this case, it is very important to be willing to clarify your thoughts and carefully verbalize them in detail.”
Saying this, Aida revealed the exercise to the participants called Blind Art Appreciation where the participants were going to view art in pairs. Specifically, one person has to close their eyes as the other verbally explains the painting shown on the front screen.
Aida developed this unique exercise in which artwork is viewed by only using words.
“It’s said that the time a visitor spends looking at a piece of artwork at an art museum is an average of about 10 seconds. But if asked about the details of the artwork after viewing it for 10 seconds, most people won’t remember them. That means that people are not looking at the information right in front of them as much as they think they are. During this workshop, the act of viewing art is being replaced with using words to communicate information, so the challenge is to understand the painting while supplementing information to each other by using your expressiveness and imagination.”
Right away, two pairs of four people sat at each table and begin the exercise. My teammate was Kosei Ikeda, the engineer mentioned above. The time limit was 10 minutes. Ikeda went first and I closed my eyes and listened to him. As soon as the painting was shown on the screen, Ikeda began giving an overview of the entire painting.
Ikeda: “A husband and wife are in a field doing farm work. It seems to be located in Europe.” Me: “What color is the field? Exactly what kind of farming are they doing?” Ikeda: “It’s brown. It looks like they are planting some kind of bulbs.” Me: “How many people are there? Are there other animals?” Ikeda: “There are two people. They are bent forward while facing each other. I can also see a cow in the distance. Or maybe it’s a donkey…”
The person explaining the painting tries to describe the painted elements in detail and the person who is listening tries to recreate the picture in their mind while asking questions about missing information. This kind of lively conversation was going on at all of the tables.
Participants tried to convey information about the picture using as many words as possible within the time limit.
When the time was up, I opened my eyes to look at the actual painting and was surprised that it was quite different from what I imagined. The picture was Potato Planters (1861) painted by the master of Western paintings, Jean-François Millet. What I realized at that moment was that I had unconsciously imagined a different work of art, Gleaners. I had associated the information provided to me by Ikeda with the information I already had in my head and assumed it was Gleaners.
Potato Planters by Jean-François Millet (1861). Since it is a famous painting, the image was flipped horizontally.
Since the visual information is being broken down into verbal information, I could not help but be bias toward my own knowledge and experiences when recreating the painting in my mind. This happened despite the fact that Ikeda divided the picture into four sections and then clearly communicated the positional relationships of the each element to avoid misunderstandings. That is the difficulty of “viewing art through words”. I personally experienced the fact that our perceptions could be distorted if we have adamant preconceptions.
Next, the pairs switched roles and moved on to view the next piece of artwork. The painting shown this time was Dynamism of a Dog on a Leash (1912) by the Italian futurism painter, Giacomo Balla. In this work, the feet of a woman in black who is walking a dachshund is painted like a multiple exposure photograph.
Dynamism of a Dog on a Leash (1912) by the Italian futurism painter, Giacomo Balla
However, it is next to impossible to explain this kind of abstract expression by only using words. As a matter of fact, at the beginning even I, who was supposed to do the explaining, did not understand what was painted (The lady looked like a giant tortoise). There was little information compared to a landscape painting and it was also difficult to explain the painted range and angle.
During the review after the exercise, we shared the ways we described the paintings that make it easier to understand. What left an impression on me was a point made by my teammate Ikeda about the importance of quantifying and specifying.
“Since numbers are perceived in the same way by everyone, it makes misunderstandings during the communication process less likely to occur. I felt it was easier to communicate by quantifying as much as possible, such as saying, ‘The size of the person is about 60% of the painting’s length.’ It’s also important to exclude any speculations and preconceptions, dismantle and rebuild the assumptions, and patiently communicate the details.” (Ikeda)
Ikeda sharing his realizations from the workshop.
This workshop made me realize that even when we look at the same thing, how we perceive and interpret that experience differs for each person. “People have their own perspectives on the same reality, so it’s important to use that as the starting point for further developing the dialogue” said Aida.
“In your own words, try to explain the facts of what is in the painting along with the interpretation of how you perceived that artwork. Communication can be established only after you share that with another person. Needless to say, not everything can be described by words. However, during discussions it’s important to exhaust your vocabulary to find out what you didn’t understand and continue thinking about it.”
After the Blind Art Appreciation exercise, the participants smiled wryly when they saw the actual images shown on the screen.
Having a discussion about life with no definitive answers to organize our own thoughts
At the end of the day, there was allotted time for discussions in the last workshop called World Cafe. For about an hour, all of the participants had a broad discussion on themes such as the ethical issues surrounding biotechnology and “What is life?”
The World Cafe’s discussions were held according to these rules. First, the participants were divided into groups of 4 to 5 people and after they exchanged simple self-introductions and decided on a theme, they discussed about it for 15 minutes. When the time was up, one host who had to remain at the table was selected and the other members moved to different tables. The host summarized what was discussed at their own table for the new members and then began a new discussion. These group discussions were held four times. The purpose of these discussions was not to draw any conclusions but rather to freely exchange opinions.
The tables I participated in discussed the themes of “Will the current bioethical rules still function when DIY bio reaches more people?” “How do we integrate the scientific and emotional perspectives on life?” and “How can religious and cultural differences in the views of life be reflected in the bioethical rules?”
The discussions were spontaneously written down on the provided paper on the table.
What was especially interesting was the discussion about “When does our life begin?” that was held with members of different backgrounds from Japan, South Korea, and Brazil. Biologically speaking, it is probably rational to consider fertilization as the beginning. The legal interpretation in Japan, however, is that a fertilized egg or fetus is not deemed as a “human” (They are called using phrases such as the emerging potential of human life) and that human rights begin at the moment of birth. But the emotional meaning of “the beginning of life” is significantly influenced by each religious perspective. For example, Catholics believe “A human should be respected as a person from the moment of conception,” while in Buddhism it is believed that “People are repeatedly reborn as part of the large flow of life” (reincarnation). With that in mind, as part of the chain of life that has continued ever since the first cell emerged on earth, and as distinctive beings with inherent genomes, we wondered exactly when our lives began.
In response to this question, Vicente Gil, a visiting foreign research fellow at the University of Tsukuba from Brazil suggested, “Isn’t the concept of life fiction in the first place?” Maybe we are just believing in the magnificent “fiction called life” and reinforcing it with religious acts such as prayers and funerals. Gil’s point, in which he deconstructed the assumption and expanded the perspective of life, left a deep impression on me.
Vincente Gil (back right)
Though the discussions had not finished and we wanted more time to delve deeper into the individual themes, the World Cafe ended after an hour. We were then divided into teams for the next day’s group work. First, the participants wrote 3 topics they were interested in and 3 things they are good at (skill sets) on a piece of paper. Then, they walked around the room holding up the paper while looking for other people with similar interests to form a team of 4 people. I joined a team of 3 members and the second day of the workshop concluded.
During the second day of the workshop we engaged in themes covering a wide range from bioinformatics, which examines life by using engineering, to ethical issues surrounding life. I think my greatest takeaway from that day was developing a sense of ownership of the fact that the problems posed by the advancements in biotechnology are indeed our own issues. At this moment when the story of life continues, how will we implement new technology that affects our own lifeness? As those who are both in control of and subjected to the technology, that is the proposition lying before us that we must continue to consider.
“What is life?” When thinking about our own lifeness, that perspective always converges with the continuous chain of life that reaches back to ancient times. Then, we realize that this question is also aimed toward us. Today, I felt like I have learned a little about how to live in this Mobius loop.
Read next
DAY3
Application possibilities
Discussions via group work and presentations on possible applications of biotechnologies in a variety of fields.